
Figure 1. Optical disk layout
Внимательный читатель, наверное, заметил, что эта часть не имеет собственного названия. Это связано с тем, что я решил поставить своеобразную логическую точку, этой статьей и мне пришлось "запихать" в нее всю оставшуюся, более-менее полезную, информацию. Поэтому приношу свои извинения за некоторую "скомканность" представленного материала.
Последняя часть оказалась самой объемной, и к моему сожалению, опять на английском. В ней вы найдете информацию о структуре пользовательских данных на оптическом диске, так же присутствует информация об обработке ошибок. И под занавес, приведена краткая информация о подмножестве SCSI команд для работы с приводами оптических дисков.
The disk is divided into various zones. In addition to the User Zone, where user data is stored, there are other zones including the PEP and SFP zones. Both the PEP and SFP contain information prerecorded by the media manufacturer and cannot be altered by a drive. They contain information about media parameters that the drive uses to read and write to the optical disk. Consult the ISO/IEC standard for more information.
Figure 1. Optical disk layout
The User Zone consists of Defect Management Areas (DMAs), a User Area and a Slipping Area. The DMAs contain information on the organization of the User Area into User Groups and Spare Groups. The DMAs also contain a Primary Defect List (PDL) and a Secondary Defect List (SDL) that provide information on the locations of defects. The drive uses this information to perform defect management.
Although the User Zone consists of tracks and sectors, it is often easier to think of it in terms of a large memory space of consecutive sectors. Figure 2 shows the following parts of the User Zone for 650-Mbyte media.
Figure 2 shows the User Zone Layout for 650-Mbyte disks. The values for g, m, and n are variable depending on how the disk is formatted.
Figure 3 and Figure 4 show the User Zone Layout for 1.3-Gbyte, for both g=1 (single data area and one spare area) and g=16 (16 data areas and 16 spare areas), respectively. It is important to note one significant difference between 650-Mbyte and 1.3-Gbyte media. Both types of media can contain multiple groups, however the start of each group on 650-Mbyte media can "slip out" with any slip spares found PRIOR to that group. The 1.3-Gbyte media establishes groups BEFORE accounting for slip spares. (Please refer to the section on Drive Defect Management for more details.)
There are 34 User/Spare groups for 1,024 bytes/sector media and 30 groups for 512 bytes/sector media. The 2.6-Gbyte media establishes groups BEFORE accounting for slip spares. (Refer to the following section, "Drive Defect Management" for more details.)
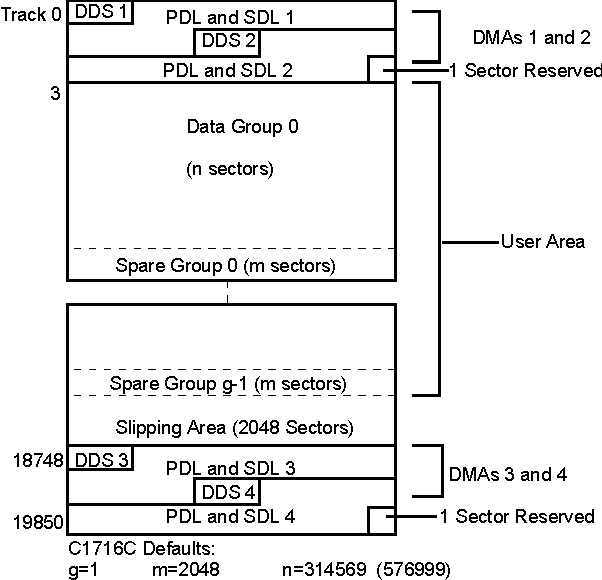
Figure 2. User Zone layout for 650-Mbyte media
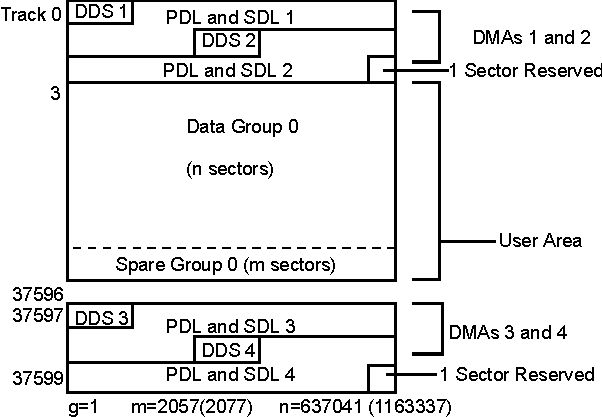
Figure 3. User Zone layout for 1.3-Gbyte media, g=1

Figure 4. User Zone layout for 1.3-Gbyte media, g=16
Table 1. Values for n and m for 1.3-Gbyte with g=16 (1,024 media)
| Band | n | m |
| Data Band 0 | 27064 | 85 |
| Data Band 1 | 28815 | 85 |
| Data Band 2 | 30498 | 102 |
| Data Band 3 | 32198 | 102 |
| Data Band 4 | 33898 | 102 |
| Data Band 5 | 35581 | 119 |
| Data Band 6 | 37281 | 119 |
| Data Band 7 | 38981 | 119 |
| Data Band 8 | 40664 | 136 |
| Data Band 9 | 42364 | 136 |
| Data Band 10 | 44064 | 136 |
| Data Band 11 | 45747 | 153 |
| Data Band 12 | 47447 | 153 |
| Data Band 13 | 49147 | 153 |
| Data Band 14 | 50830 | 170 |
| Data Band 15 | 52462 | 187 |
The format of 1.3-Gbyte media is often referred to as a "sliding sector" format. This means that logical tracks do not necessarily align with physical revolutions. The following table details the physical revolution to logical track layout for 1.3-Gbyte media.
Table 2. Physical Revolution to Logical Track Layout
| Zone or Band | Physical Revolution Range | Logical Track Range |
| Inner SFP | (-369, -161) | (-369, -161) |
| Inner Mfg | (-128, -33) | (-128, -33) |
| Data Band 0 | (0, 1349) | (0, 1599) |
| Data Band 1 | (1350, 2699) | (1600, 3299) |
| Data Band 2 | (2700, 4049) | (3300, 5099) |
| Data Band 3 | (4050, 5399) | (5100, 6999) |
| Data Band 4 | (5400, 6749) | (7000, 8999) |
| Data Band 5 | (6750, 8099) | (9000, 11099) |
| Data Band 6 | (8100, 9449) | (11100, 13299) |
| Data Band 7 | (9450, 10799) | (13300, 15599) |
| Data Band 8 | (10800, 12149) | (15600, 17999) |
| Data Band 9 | (12150, 13499) | (18000, 20499) |
| Data Band 10 | (13500, 14849) | (20500, 23099) |
| Data Band 11 | (14850, 16199) | (23100, 25799) |
| Data Band 12 | (16200, 17549) | (25800, 28599) |
| Data Band 13 | (17550, 18899) | (28600, 31499) |
| Data Band 14 | (18900, 20249) | (31500, 34499) |
| Data Band 15 | (20250, 21599) | (34500, 37599) |
| Outer Mfg | (21600, 22949) | (37600, 37785) |
| Outer SFP | (22950, 24299) | (37786, 38046) |
| 1X | 2X | 4X | |
| bytes per sector | 1,024 (512) | 1,024 (512) | 1,024 (512) |
| track pitch | 1.60 | 1.39 | 1.15 |
| spiral direction | outward | outward | inward |
| data encoding | (2,7)RLL | (2,7)RLL | (1,7)RLL |
| channel bits per byte | 16 | 16 | 12 |
| raw bytes per sector | 1,360 (746) | 1,360 (746) | 1,410 (799) |
| headers aligned | yes | no | yes |
| sectors per revolution ID | 17 (31) | 20.1 (36.7) | 33 (58) |
| sectors per revolution OD | 17 (31) | 40.3 (73.5) | 66 (116) |
| modulation method | PPM | PPM | PWM |
| bit density ID (bpi) | 24.9K | 29.5K | 48.7K (49.1K) |
| bit density OD (bpi) | 12.5K | 29.5K | 50.9K (50.8K) |
| sectors per logical track | 17 (31) | 17 (31) | 17 (31) |
| number of user bands | 1 | 16 | 34 (30) |
| physical tracks per band | 18,751 | 1,350 | 765 (868) |
| physical tracks per user zone | 18,751 | 21,600 | 26,010 (26,040) |
| logical tracks per user zone | 18,751 | 37,473 (37,527) | 75,732 (73,077) |
| logical tracks per band ID | 1,600 | 1,485 (1,624) | |
| logical tracks per band OD | 3,100 | 2,970 (3,248) | |
| number of sectors for spares | 4,096 | 2,057 (2,077) | 5,287 (6,479) |
| number of buffer/test sectors | 0 | 0 | 9,112 (16,616) |
| number of sectors for DMAs | 102 (186) | 102 (186) | 170 (310) |
The C1716T drives support the defect management scheme specified by ISO 10089A and ISO 11560, and ISO/IEC 14517. Each DMA consists of a
The DDS contains information on how the disk is organized into user and spare groups. There are three important parameters; the variables g, n, and m are used in the ISO standard, and are used here for consistency:
User data is stored initially in the sectors of the User Group, while the Spare Groups are reserved sectors for the linear replacement sparing algorithm. The values of g, n, and m are generally chosen so that they maximize the number of spare sectors allowed, and maximize the size of the User Area.
The ISO/IEC standard for 650-Mbyte media allows for a maximum of 2048 spare sectors total from the PDL and the SDL. The standard for 1.3-Gbyte usable capacity per disk (Gb) allows for 2057 or 1077, depending on the sector size of 1,024 or 512 bytes per sector. The standard for 2.6-Gbyte media allows for 5202 or 558, depending on the sector size of 1,024 or 512 bytes per sector. For 1.3-Gbyte the value for g must be 1 or 16: for 2.6-Gbyte media, the value for g must be 34.
In general for 650-Mbyte: g * (n + m) <= (size of User Area)
In general for 1.3-Gbyte: g = 1 or 16, (n, m or n0 through n15 and m0 through m15 are predefined based on g).
In general for 2.6-Gbyte: g = 34 or 30.(n, m or n0 through n33/29 and m0 through m33/29 are predefined based on g)
For more details consult the ISO/IEC standard.
The PDL contains a list of defective sector addresses as determined by the manufacturer or by a certification of the User Area, i.e. during a SCSI Format Unit Command. Defective sectors listed in the PDL are managed according to the slip sparing algorithm described in this chapter.
The SDL contains a list of defective sectors and corresponding replacement sectors determined during disk use, after certification. Defect/replacement entries in the SDL are managed according to the replacement sparing algorithm described in this chapter.
The Slipping Area is a portion of the User Zone used by the slip sparing algorithm. Defects found during certification are excluded from use. The user accessible space is slipped by a corresponding number of sectors into the slip area.
This area is large enough to account for a maximum of 2048 slip spares. Any unused sectors in the slipping area are unavailable for user data.
NoteThe Slipping Area applies only to 650-Mbyte media.
The slip sparing algorithm is used to manage the defective sectors listed in the PDL during address translation between logical and physical blocks. During an address translation, the logical blocks are "slipped" past any defective sectors, thus the name slip sparing. As an example, suppose there are defective sectors at physical block addresses 20 and 30, and the user wants the physical address of logical block 40. Since physical addresses 20 and 30 have defective sectors they should be slipped past, so logical block address 20 is now physical block address 21, and logical block address 30 is now physical block address 32, taking into account both physical blocks 20 and 30 being slipped past. This would result in physical block address 42 being the translation for logical block address 40.
This is not a truly accurate example for the following reasons:
For 650-Mbyte media, slip sparing is always the first step of address translation, followed by User and Spare Grouping, and replacement sparing.
For 1.3-and 2.6-Gbyte media, user and Spare Grouping is always the first step of address translation, followed by Slip sparing, and replacement sparing.
The data structures for slip sparing and User and Spare Grouping (the PDL and DDS respectively) are created or updated only during a certification/format process, such as during a SCSI Format Unit Command. After certification, any additional defect management updating is done through the replacement sparing algorithm.
The replacement sparing algorithm is intended to manage defective sectors found after initialization.
As was mentioned earlier, the DDS allows for a number of sectors to be reserved for future use by the replacement sparing algorithm. These "spare sectors" reside in the Spare Groups, and are referred to via entries in the SDL. Each SDL entry consists of a defect and its replacement pair. The defect is always a sector in a User Group, and the replacement is a sector from a Spare Group. Both are given in track/sector form.
During address translation, after the original physical address is found via the slip sparing algorithm, the SDL is checked to see if that physical address was spared through the replacement sparing algorithm. If so, the replacement physical address is substituted for the original physical address.
In the event a sector needs to be replaced, i.e., due to a Reassign Blocks Command or automatic reallocation during a write command, a new defect/replacement pair is added to the SDL (if the new defect is not already in the SDL) or an existing defect/replacement entry is updated if it already exists in the SDL. (Updating an existing defect/replacement pair only occurs on 650-Mbyte media. For 1.3- and 2.6-Gbyte media, a new defect/replacement pair is added, thus creating a "chain" of defect/replacement pointers.)
Although not directly related to disk format, the various error thresholds are the basis for deciding whether or not to spare a sector. This could happen during the certification process (i.e. the slip sparing algorithm) or auto-reallocation during a SCSI Write command (i.e. the replacement sparing algorithm). These error thresholds are related to the format of a sector in the User Zone.
Each sector in the User Zone consists of a header, user data, and parity bytes for error correction. The first error threshold of importance involves information in the sector header. Each header consists of three copies of the sector's track number, sector number, and a Cyclic Redundancy Check (CRC). The error threshold is determined by the number of sectors found "good."
The other error threshold of interest pertains to the degree of error correction required on the data. The error correction code (ECC) used causes parity bytes to be written following the user data. During a data recovery operation, these bytes are used to detect and correct up to 8 defective bytes in an interleave. Each sector has 10 (5) interleaves with 120 (122) bytes in each interleave. The actual number of bytes per interleave requiring correction is used as an error threshold. Consult the ISO standard for more details.
Table 4 shows the error thresholds for the C1716T (2X), and C1113 (4X) optical drives. The sector IDs column refers to the minimum number of sector IDs that must be read correctly for the corresponding operation to be deemed successful. The ECC level column refers to the maximum number of bytes per interleave that require correction in order for the corresponding operation to be deemed successful.
| Operation | Sector IDs | ECC Level |
| Format | C1716T = 2 C1113 = 1 | 3 |
| Write | 2 | - |
| Erase | 2 | - |
| Verify | 2 | 4 |
| Read (recovered) | 1 | 7 |
| Read | 1 | 8 |
The following SCSI-2 commands, listed numerically by group, can be used with the optical disk jukebox.
| Note | Detailed descriptions of these commands and their
functionality with optical products can be found in the following documents: •Offline Diagnostics for Hewlett-Packard Optical Products. • American National Standards Institute (ANSI) document titled, Small Computer System Interface - 2 (SCSI-2), revision 10H which is dated September, 1991. |
| Code (Hex.) | Name | Description |
| 00 | Test Unit Ready | Provides a means to check if the logical unit is ready |
| 01 | Rezero Unit | Moves the optical head to its recalibration position |
| 03 | Request Sense | Requests the detailed error information |
| 04 | Format Unit | Initializes the optical disk (done only once for unformatted, write-once disks) |
| 07 | Reassign Blocks | Reassigns defective sectors |
| 08 | Read | Reads data from the specified logical block address |
| 0A | Write | Writes data to the specified logical block address |
| 0B | Seek | Moves the optical head to the physical track where the specified logical block exists |
| 12 | Inquiry | Reads the information related to the controller and the drive unit |
| 15 | Mode Select | Sets optical disk, drive unit, or controller unit parameters |
| 16 | Reserve | Gains the exclusive control of a specified logical unit |
| 17 | Release | Releases a specified logical unit from the reservation state |
| 1A | Mode Sense | Reads optical disk, drive unit, or controller unit parameters |
| 1B | Start/Stop Unit | Starts or stops rotating the optical disk, and/or ejects the optical disk from the drive unit |
| 1C | Receive Diagnostic Results | Requests analysis data be sent to the initiator |
| 1D | Send Diagnostic | Requests the disk controller to perform diagnostic tests |
| 1E | Prevent/Allow Medium Removal | Prevents or allows removal of the optical disk in the logical unit |
| Code(Hex.) | Name | Description |
| 25 | Read Capacity | Reads the capacity of the optical disk |
| 28 | Read | Reads data from the specified logical block address |
| 2A | Write | Writes data to the specified logical block address |
| 2B | Seek | Moves the optical head to the physical track where the specified logical block exists |
| 2C | Erase | Executes erase operation from the specified logical block address on rewritable disks only |
| 2E | Write and Verify | Writes data to the optical disk and then verifies the written data by checking the error correction code |
| 2F | Verify | Verifies the data starting from the specified logical block address by checking the error correction code |
| 34 | Pre-Fetch | Reads the data from the specified logical block address into the drive's controller cache memory |
| 35 | Synchronize Cache | Initiates the writing of all cached write data to the optical disk |
| 37 | Read Defect Data | Reads the optical disk defect information |
| 3B | Write Buffer | Writes data to the controller data buffer |
| 3C | Read Buffer | Reads data from the controller data buffer |
| 3E | Read Long | Reads data from the specified logical block address including ECC data |
| 3F | Write Long | Writes data to the specified logical block address without using the ECC generation circuitry |
| 4C | Log Select | Clears drive resident logs and odometers |
| 4D | Log Sense | Reads drive resident logs and odometers |
| 55 | Mode Select | Sets optical disk, drive unit, or controller unit parameters |
| 5A | Mode Sense | Reads optical disk, drive unit, or controller unit parameters |
| Code (Hex.) | Name | Description |
| A8 | Read | Reads data from the specified logical block address |
| AA | Write | Writes data to the specified logical block address |
| AC | Erase | Executes erase operation from the specified logical block address on rewritable disks only |
| AE | Write and Verify | Writes data to the optical disk and then verifies the written data by checking the error correction code |
| AF | Verify | Verifies the data starting from the specified logical block address by checking the error correction code |
| B7 | Read Defect Data | Reads the optical disk defect information |
Приведенный выше материал дает некоторую пищу для дальнейших размышлений. Например, подозрения о том, что оптические приводы на 3.5" (в случае если они имеют отличия в формате, а что скорее всего так и есть) не могут быть использованы на станции, без модификации станционного ПО, еще более усилились. Тем, кто хоть раз пытался извлечь не размонтированный диск из станции, наверняка, после прочтения материала, пришла мысль о том, что при выполнении команд MOUNT-DISK, UNMOUNT-DISK выполняется SCSI команда 1E "Prevent/Allow Medium Removal". А может и не выполняется! :-) Т.к. нам, простым пользователям Системы 12, остается только догадываться о конкретной реализации станционного ПО системы ввода/вывода. За сим, позвольте раскланяться и закрыть тему оптических дисков... на текущий момент.
Максим Осташов
Размещено на www.s12most.mailru.com 9 апреля 2001
Есть вопросы или дополнения, конструктивная критика? Пишите!